This post is about a tunnel technology used by routers called VXLAN.

-----------------------------------------------------------------------------------------------------------
Referred links:
https://networkdirection.net/articles/routingandswitching/vxlanoverview/
https://medium.com/@NTTICT/vxlan-explained-930cc825a51
http://www.virtualizationteam.com/network/vxlan-concept-simplified.html
https://sites.google.com/site/amitsciscozone/home/data-center/vxlan
https://tools.ietf.org/html/rfc7365:
Framework for Data Center (DC) Network Virtualization
--------------------------------------------------------------------------------------------------------------
VXLAN is a formal internet standard, specified in RFC 7348. If we go
back to the OSI model, VXLAN is another application layer-protocol based
on UDP that runs on port 4789.
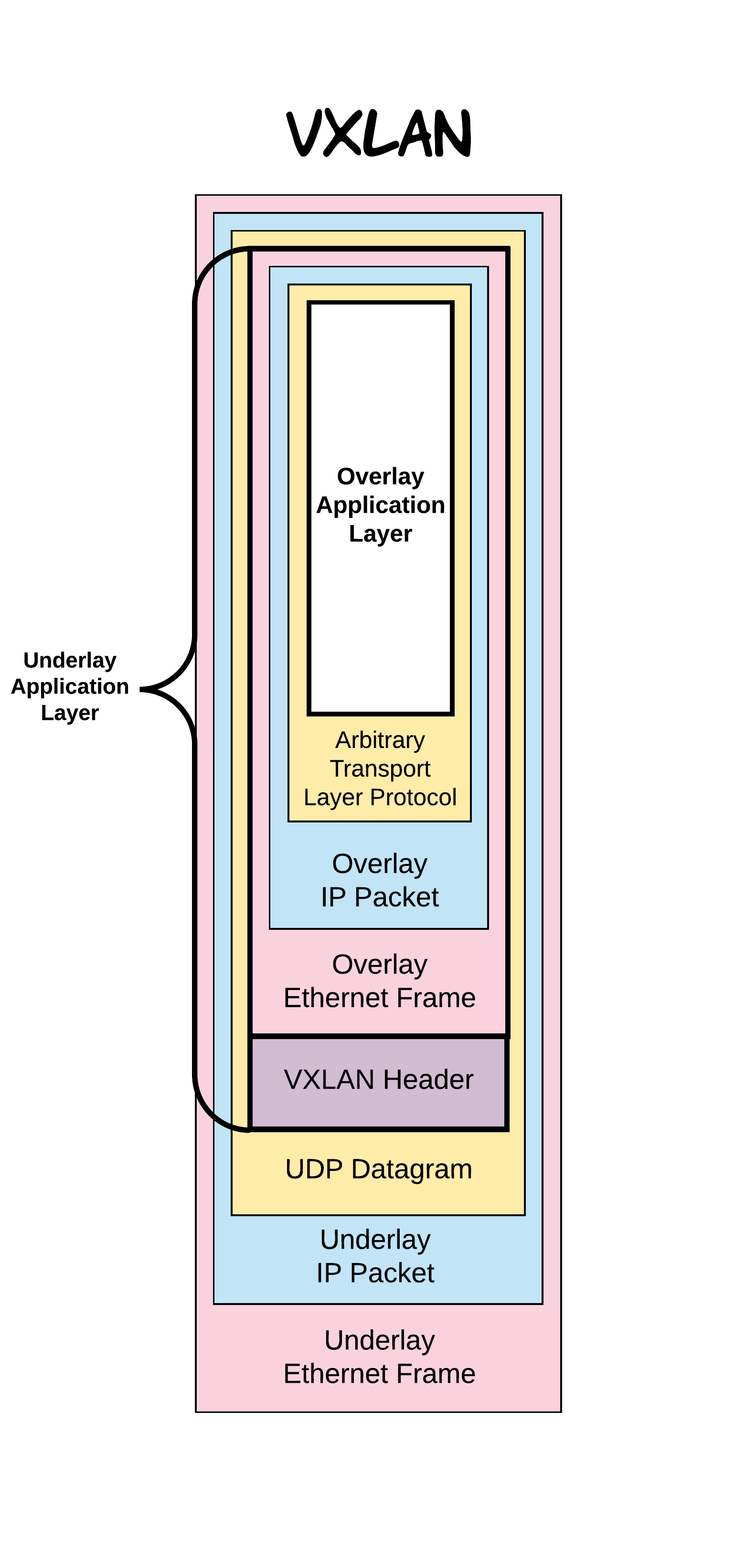
At its most basic level, VXLAN is a tunnelling protocol. In the case of
VXLAN specifically, the tunnelled protocol is Ethernet. In other words,
it’s merely another Ethernet frame put into a UDP packet, with a few
extra bytes serving as a header — or a transport mechanism that supports
the software controlling the devices that use the VXLAN.
Virtual Extensible LAN (VXLAN) is an encapsulation protocol for
running an overlay network on existing Layer 3 infrastructure.
An
overlay network is a virtual network that is built on top of existing
network Layer 2 and Layer 3 technologies to support elastic compute
architectures.
VXLAN makes it easier for network engineers to scale
out a cloud computing environment while logically isolating cloud apps
and tenants.
From the packet switching point-of-view, VXLAN is just a
matter of sticking some encapsulation on top of an L2 frame: something
that other protocols do as well. The real difference it makes is at the control and management layer.
Need to mention is its available hardware support. While VxLAN can run
well in software, some platforms implement VxLAN in hardware.
However, it does require multicast-enabled IP network and adjustment of
MTU size on physical devices.
Ideally, one logical Layer 2 network is associated with one multicast
group address. Sixteen million logical Layer 2 networks can be
identified in VXLAN, using 24 bit field in the encapsulation header, but
the multicast group addresses are limited (224.0.0.0 to
239.255.255.255). In some scenarios it might not be possible to have one
to one mapping of a logical Layer 2 network to multicast group address.
In such scenarios the vCloud Networking and Security Manager maps
multiple logical networks to a multicast group address
Also, the lack of control-plane in some setups means MAC
address learning is done dynamically which could cause scalability
problems.
Benefits of VXLAN over pure L2
1.
Probably
the greatest advantage a VXLAN solution has over a pure Layer 2 (L2)
network is the elimination of the risks associated with L2 domains
spanning multiple logical switches. For instance, an entirely L3 network
with a VXLAN overlay is not susceptible to the spanning tree faults
that have been experienced by some major Australian organizations.
Using STP to provide L2 loop free topology disables most redundant
links. Hence, Equal-Cost Multi-Path (ECMP) is hard to achieve. However,
ECMP is easy to achieve in IP network.
2.
Additionally,
VXLAN is more scalable than pure L2, especially when control-plane
learning is implemented, because excessive BUM (broadcast, unknown
uni-cast and multicast) frame flooding is suppressed. This, combined
with
the fact that hardware VTEPs (explained below) minimize the latency
overhead of VXLAN
implementations, means we can build a network that is more scalable and
robust, without sacrificing performance.
3.
Due to Server virtualization, each Virtual Machine (VM) requires a
unique MAC address and an IP address. So, there are thousands of MAC
table entries on upstream switches. This places much larger demand on
table capacity of the switches.
4.
VLANs are too restrictive in terms of distance and deployment. VTP
can be used to deploy VLANs across the L2 switches but most people
prefer to disable VTP due to its destructive nature.
5.
One historical concern with VLANs is the limited address space. Each
device can have around 4000 usable VLANs. This is an issue with service
providers. They may have to maintain several VLANs per customer, which
exhausts the address space quickly. To work around this VLAN ID’s can be
reused on different switches, or technologies like Q-in-Q can be used.
VxLAN does not have this limitation. It uses a 24-bit header, which
gives us about 16 million VNI’s to use. A VNI is the identifier for the
LAN segment, similar to a VLAN ID. With an address space this large, an
ID can be assigned to a customer, and it can remain unique across the
entire network.
Overlay or underlay?
Overlay
and underlay are terms frequently used in SDN and network
virtualization. In terms of VXLAN, the underlay is the Layer 3 (L3) IP
network that routes VXLAN packets as normal IP traffic. The overlay
refers to the virtual Ethernet segment created by this forwarding.
Today
is the time of cloud computing and extensive usage of data centers,
where VXLAN is playing an important role for some companies, not to
forget it has competitors too:)
For example, a L3 VXLAN switch (e.g. Cumulus), upon receiving a frame, may do any of the following:
· switch it locally if it is destined for a locally learnt MAC address (traditional Ethernet switching)
· forward it through a local VTEP, hence pushing it into the underlay encapsulated in VXLAN (in the overlay)
· route it at L3, pushing it into the underlay unencapsulated, which is just another IP packet.
Interaction between Overlays and Underlays
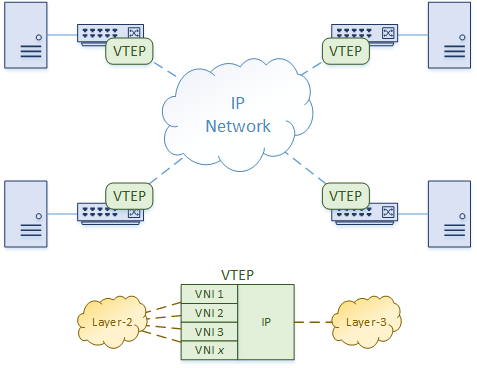
Introducing VTEP
The
term VTEP (VXLAN Tunnel Endpoint) generally refers to any device that
originates or terminates VXLAN traffic.
The encapsulation and decapsulation are handled by a component called a VTEP (VxLAN Tunnel End Point). In the Cisco Nexus platform, this is also called an NVE interface.
There are two major types, based
on how the encapsulation or de-encapsulation of VXLAN packets is
handled: hardware VTEP devices handle VXLAN packets in hardware, while
software VTEP devices handle VXLAN packets in software.
Examples
of hardware VTEPs include switches and routers such as Cumulus
switches, as we use in NTT’s environment. Software VTEPs include servers
and hypervisors such as NSX-enabled ESXi hosts.
More
specifically, a VTEP can refer to a virtual interface similar to an SVI
that exists on such a device. Such an interface will often connect to
the local device’s internal bridge implementation and act as the local
source of VXLAN frames and the destination for remote MACs.
As we have seen, VxLAN traffic is encapsulated before it is sent over
the network. This creates stateless tunnels across the network, from the
source switch to the destination switch.

As shown in the diagram below, a VTEP has an IP address in the
underlay network. It also has one or more VNI’s associated with it. When
frames from one of these VNI’s arrives at the Ingress VTEP, the VTEP encapsulates it with UDP and IP headers.
The encapsulated packet is sent over the IP network to the Egress VTEP. When it arrives, the VTEP removes the IP and UDP headers, and delivers the frame as normal.
Packet Walk
Let’s take a moment to see how traffic passes through a simple VxLAN network.

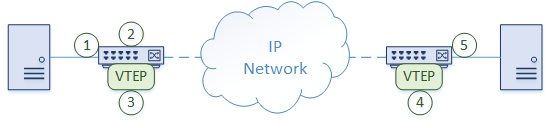
- A frame arrives on a switch port from a host. This port is a regular
untagged (access) port, which assigns a VLAN to the traffic
- The switch determines that the frame needs to be forwarded to
another location. The remote switch is connected by an IP network. It
may be close or many hops away
- The VLAN is associated with a VNI, so a VxLAN header is applied. The
VTEP encapsulates the traffic in UDP and IP headers. UDP port 4789 is
used as the destination port. The traffic is sent over the IP network
- The remote switch receives the packet and decapsulates it. A regular layer-2 frame with a VLAN ID is left
- The switch selects an egress port to send the frame out. This is
based on normal MAC lookups. The rest of the process is as normal
Tips to remember:
1.
It is important that the underlay is configured and working before the
overlay is configured. Problems in the underlay will lead to problems in
the overlay.
2.
The L2VNI is the bridge domain. This is for bridging hosts on the same layer-2 segment.
An L3VNI can be used to route between L2VNI’s. The ingress or egress VTEP can perform routing. This is called Symmetric IRB. Another form of routing called Asymmetric IRB,
uses the ingress VTEP for routing and bridging, while the egress VTEP
can only do bridging. Not a lot of vendors support asymmetric IRB.
A VTEP needs to know about all locally used L2VNI’s. It does not need
to know about any L2VNI’s that it doesn’t need to support. A VTEP also
needs to know about all L3VNI’s in use across the network.
3.
Multitenancy
Each L3VNI can be associated with a VRF. This makes multitenancy possible, in a similar way to MPLS.
Each VRF is still configured with a Route Distinguisher to keep it
unique. Reachability information is imported and exported with Route
Targets. Remember that you will need extended communities for this.
Each tenant can have one L3VNI, and many L2VNI’s.
4.
VxLAN is vendor-independent, so there are different ways it can be deployed. The two primary ways are Host Based and Gateway.
Hosts, such as a hypervisor, can have
VxLAN configured on their virtual switches. Other devices, like
firewalls and load-balancers, may also speak VxLAN natively.
In cases like this, there is no need to translate VLANs to VNI’s.
Furthermore, the VTEPs are on the hosts themselves. The physical network
infrastructure sees IP traffic, not VxLAN.
If the hosts do not support running VxLAN natively, or they just don’t use it, the switches can act as a VxLAN Gateway. Hosts belong to a VLAN. The switches map the VLAN to a VNI, and provide the VTEP functions.
In this model, the hosts are unaware of VxLAN, as the switches do all the work.
One advantage of this method is that VxLAN may (depending on
platform) be implemented in hardware, providing performance benefits.

Of course, a combination of these two methods can be used. The
switches can provide gateway services to some hosts, while other hosts
speak VxLAN natively.
5.
VXLAN encapsulation adds between 50 and 54 bytes of additional header
information to the original Ethernet frame.
Because this can result in Ethernet frames
that exceed the default 1514 byte MTU, best practice is to implement jumbo frames
throughout the network,VxLAN adds quite a bit of overhead, so we need to increase the MTU size.
If we don’t do this, we may end up with fragmented packets, which can
decrease performance.
6.
When multiple overlays co-exist on top of a common underlay network, resources like bandwidth should be provisioned to ensure that traffic form overlays can be accommodated and QoS objectives can be met.
Overlays can have partially overlapping paths (nodes and links). Each overlay is selfish by nature.it sends traffic so as to optimize its own performance
without considering the impact on other overlays, unless the underlay
paths are traffic engineered on a per-overlay basis to avoid
congestion of underlay resources.
Better
visibility between overlays and underlays, or general coordination in
placing overlay demands on an underlay network, may be achieved
by providing mechanisms to exchange performance and liveliness
information between the underlay and overlay(s) or by the use of such
information by a coordination system.
Such
information may include:
-
Performance metrics (throughput, delay, loss, jitter)
-
Cost metrics
7.
interface Vxlan 1
vxlan source-interface loopback 1
vxlan vlan 100 vni 10100
vxlan vlan 200 vni 10200
vxlan vlan 100 flood vtep 2.2.2.2 4.4.4.4
vxlan vlan 200 flood vtep 2.2.2.2 3.3.3.3 4.4.4.4